Pipelines
NetOrca Pack Pipelines are automated workflows that seamlessly connect individual AI processors to streamline the entire journey from configuration generation to service delivery. By chaining together CONFIG, VERIFY, and EXECUTION stages, pipelines eliminate manual handoffs and reduce the manual effort required for infrastructure management, enabling teams to deliver services faster and more reliably. The total cost of a pipeline is calculated by the sum of individual response costs, across all pipeline stages.
States of pipeline stages
The state of a pipeline represents its current operational state for that stage. This field shows whether the pipeline has completed, failed, been scheduled for execution, or is waiting for a response. The table below shows all values of state and their meanings:
state |
Description |
|---|---|
OK |
Pipeline stage completed successfully. |
FAILED |
Pipeline stage execution failed. |
SCHEDULED |
Request queued for execution. |
WAITING_FOR_RESPONSE |
Request has been sent and is actively waiting for response. |
Triggers
There are 3 ways to trigger a NetOrca Pack Pipeline:
- Automatically via Change Instance Approval.
- Trigger an AI Processor via endpoint directly.
- Push a PackData for each stage manually via API.
When each stage is finished successfully, the next stage will be triggered automatically if there exists an active AI processor for the next stage.
1. Automatically via Change Instance Approval
When a Config AI Processor is set up for a Service, the approval of any Change Instance related to that Service will automatically start the CONFIG stage. If auto-approval is enabled for a Service, the Change Instance will be approved immediately upon consumer submission, which will also trigger the Config AI Processor. With this option, the infrastructure configuration for the Service Item will be created or updated immediately after consumer submission, ensuring the fastest possible processing with no delay.
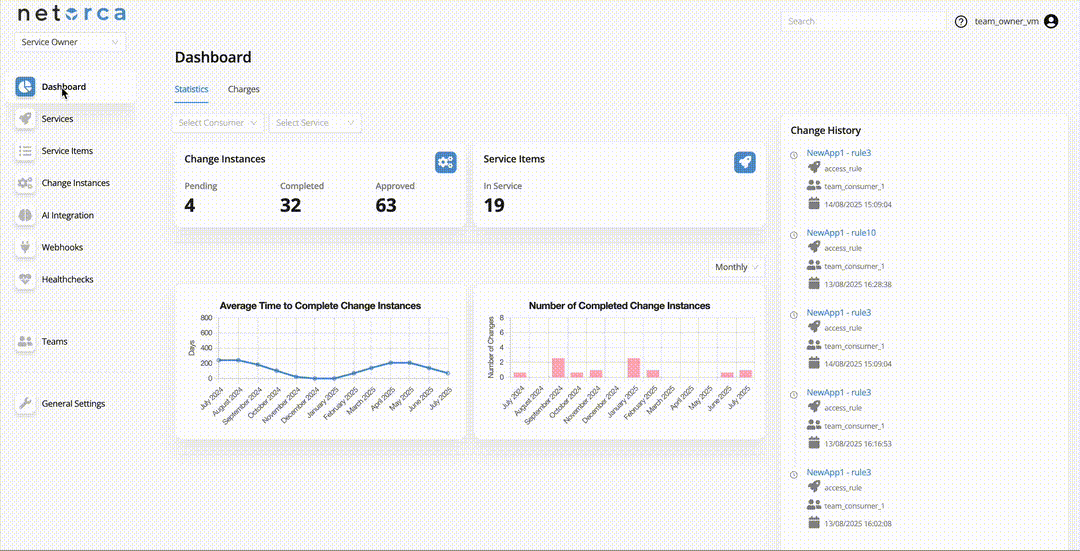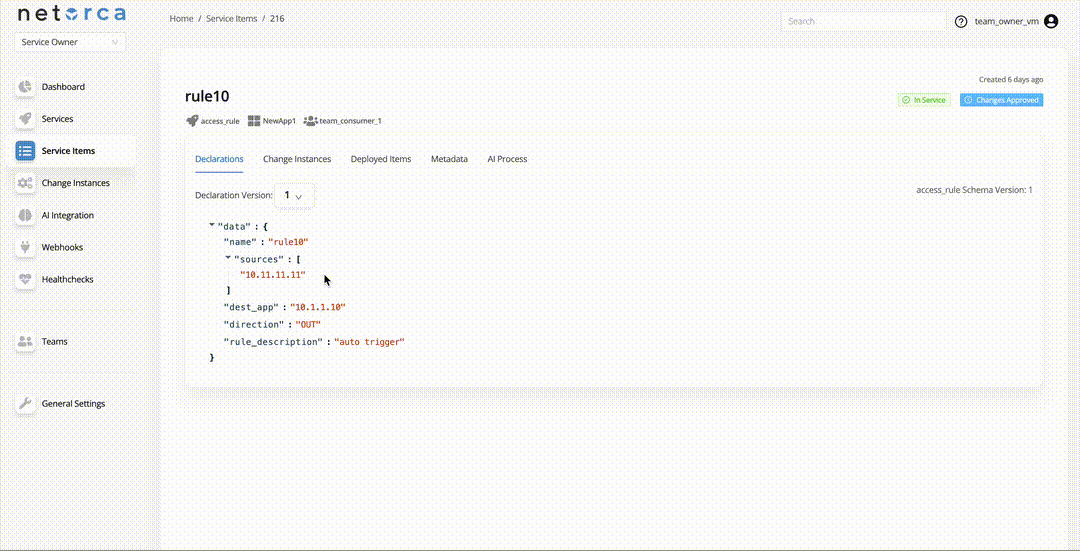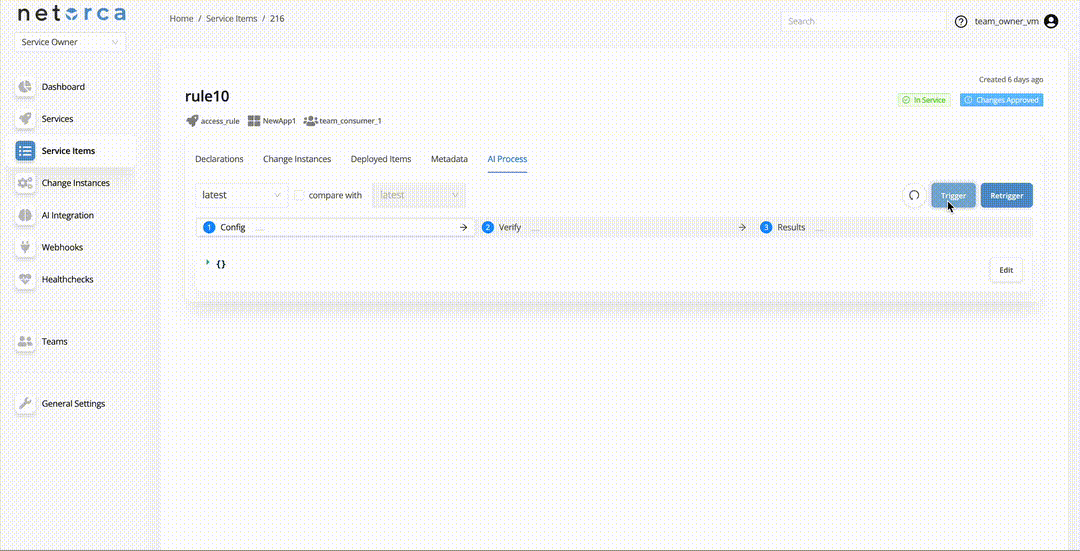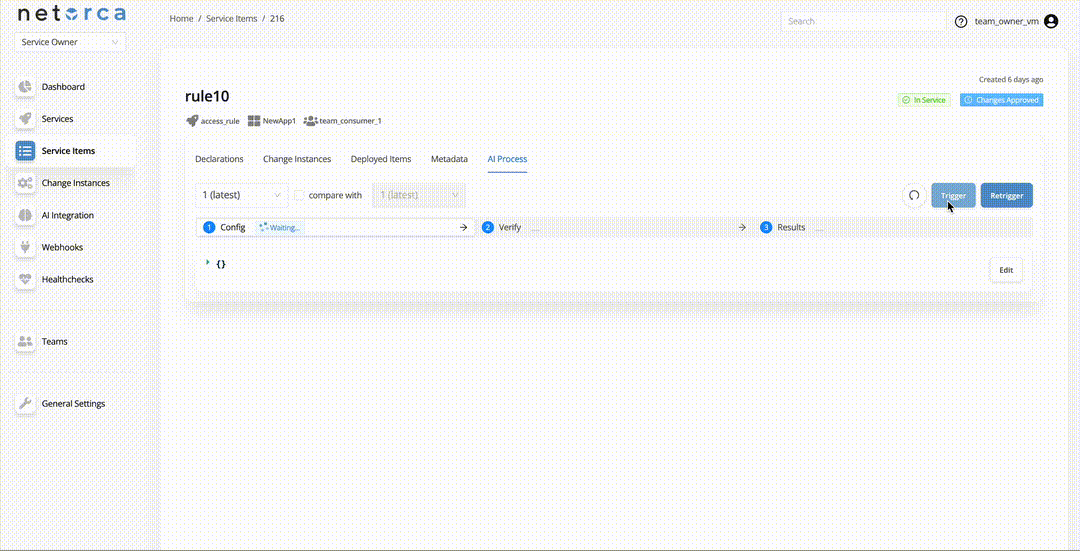
2. Trigger an AI Processor via endpoint directly
Service Owners can trigger an active AI Processor directly via an endpoint. This will take the latest approved declaration of the Service Item and initiate the pipeline. Each stage can be triggered separately, provided the PackData from the previous stage exists. To do so:
Retrigger
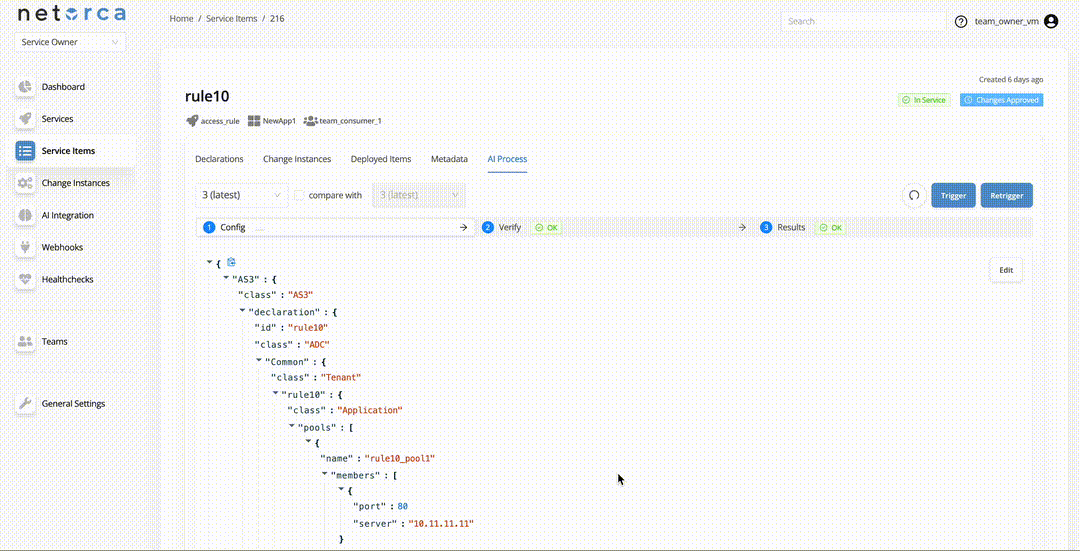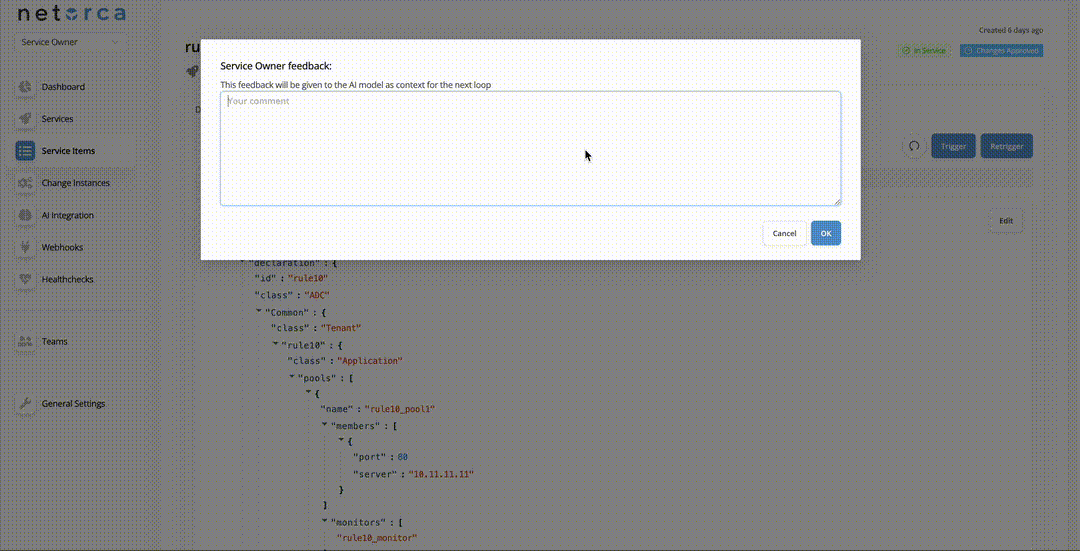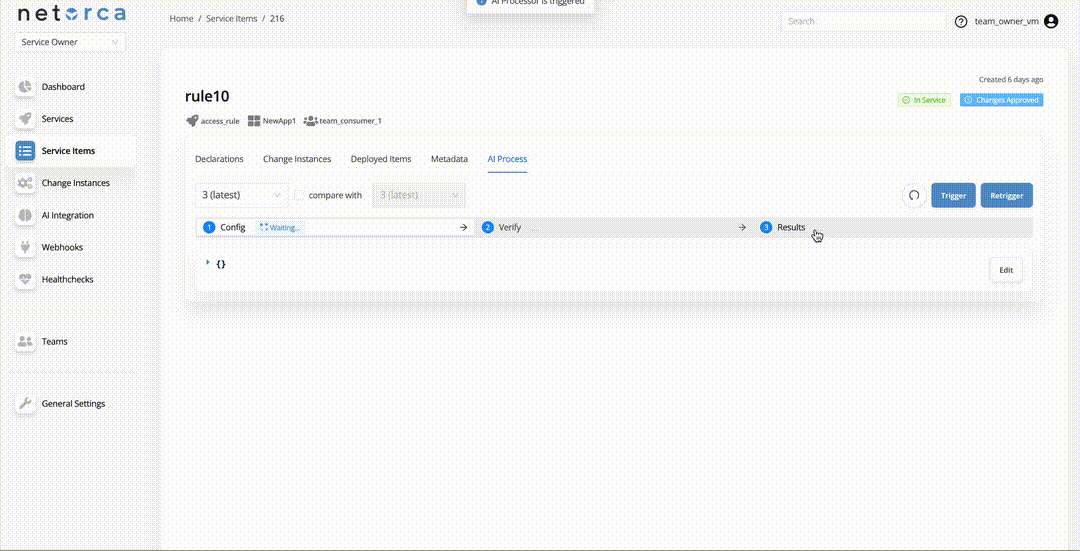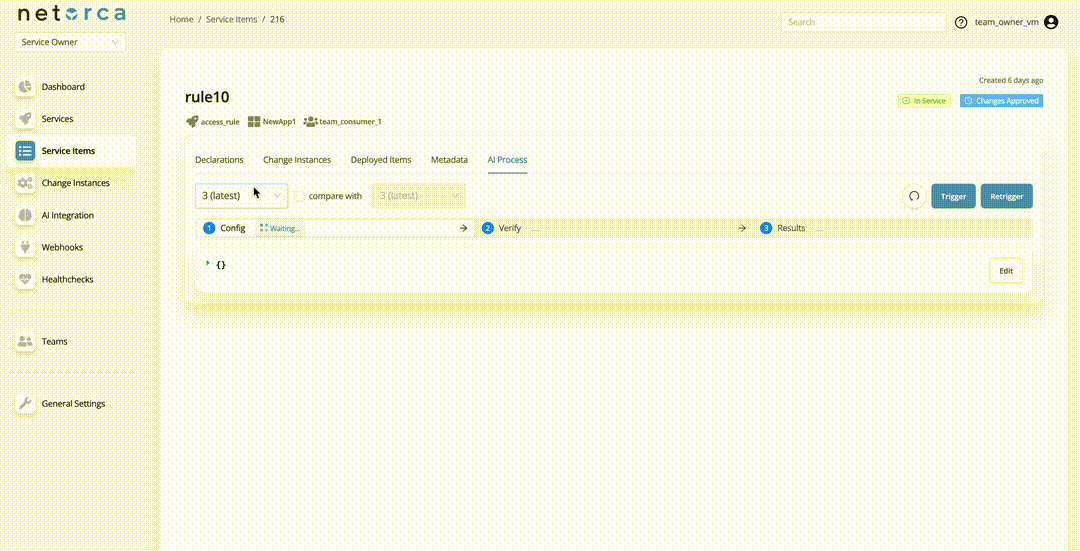
The Retrigger endpoint restarts the entire pipeline from the CONFIG stage while preserving the previous execution context. This is useful when troubleshooting failed executions. A Service Owner can also provide a feedback comment, which becomes part of the execution context to help the self-healing mechanism correct the config. To retrigger a pipeline:
3. Push a PackData for each stage manually via API
Each stage of NetOrca Pack Pipeline does not always have to be generated directly by the AI Processor or LLM. Service Owners can provide PackData from external services, scripts, or testing frameworks and insert it into any stage in the pipeline, effectively replacing or augmenting the AI-driven step.
For example, CONFIG and VERIFY Pack Data can be generated by the AI Processor, while an external script can take the both stage data and run tests in a simulation environment. If errors are detected, the script can push the error details back into the EXECUTION stage, which may then retrigger the workflow for self-healing. In this retriggered cycle, the CONFIG AI Processor will have the error context available, allowing it to attempt an automatic fix.
To directly push the PackData for each stage, use the following endpoints:
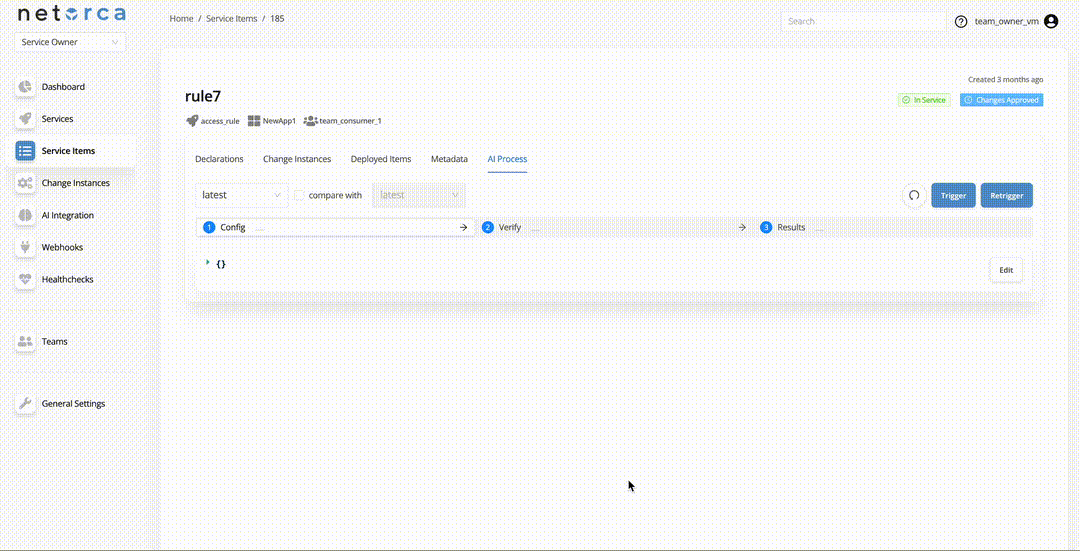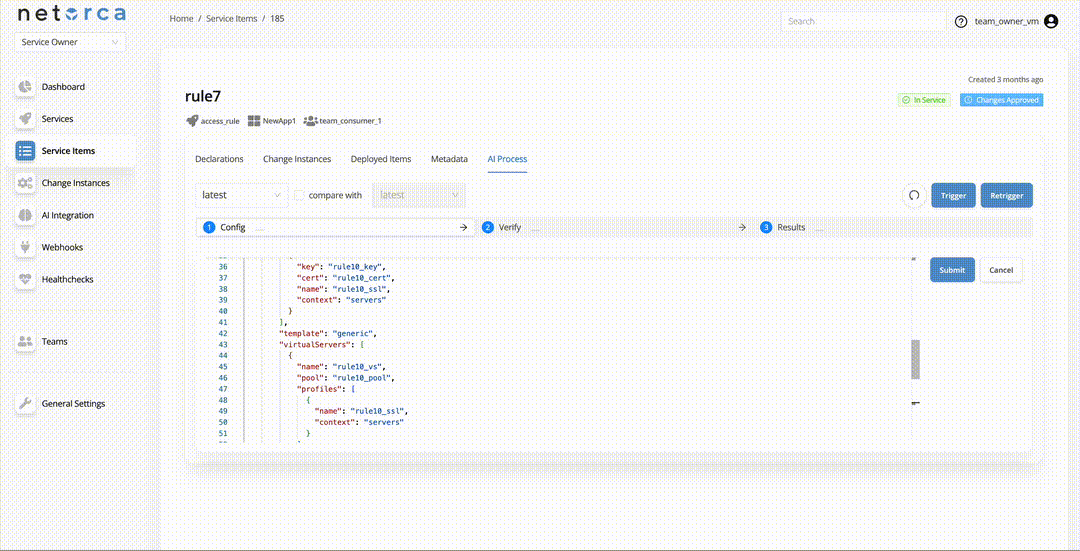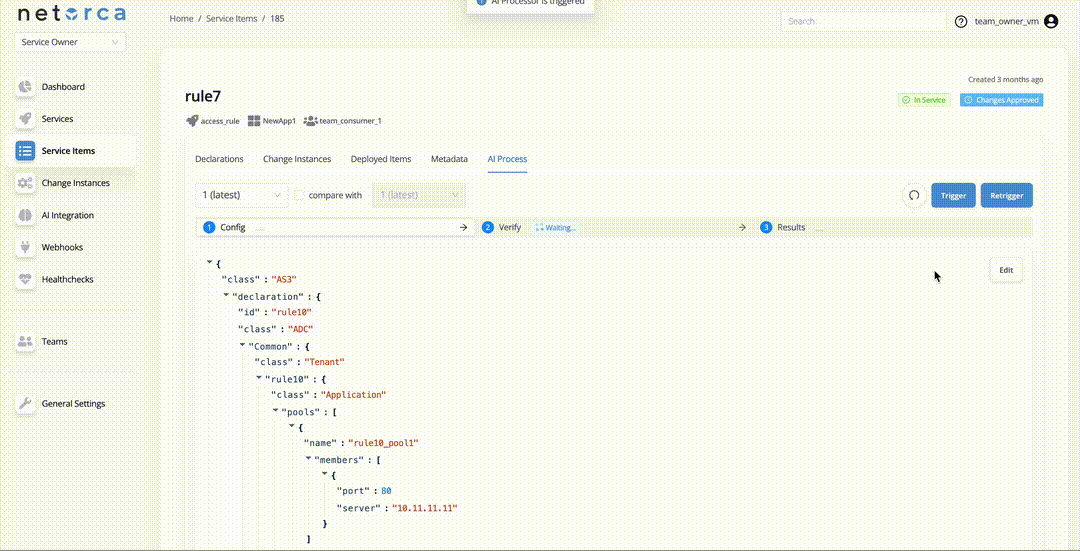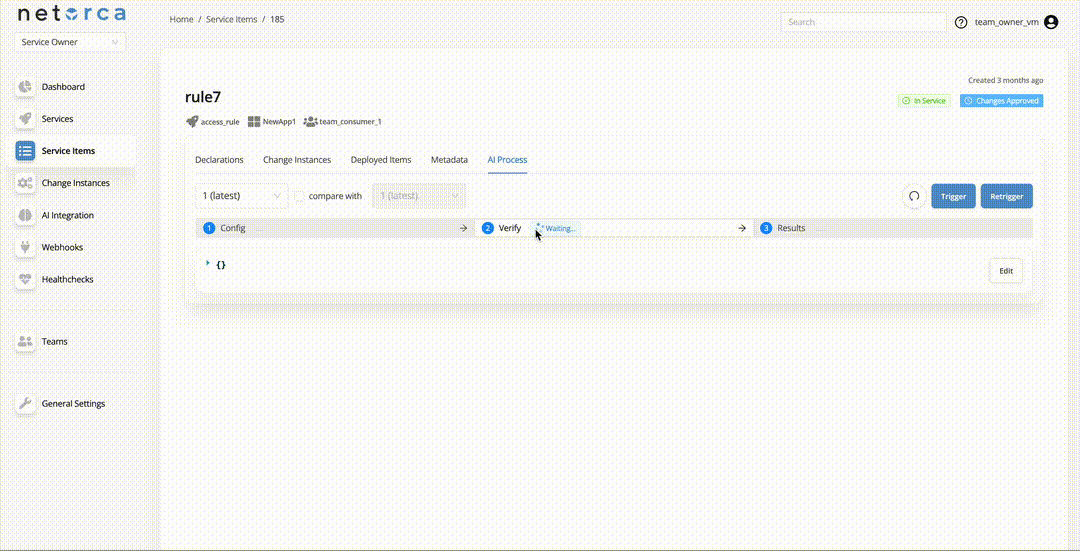
If an AI Processor is available and active for the next stage, it will be triggered, automatically.